Hacking lpegrex into several small pieces (2023)
(Note: this will become a video soon - I hope...)
Update: this will become a part of my presentation in the EmacsConf2023.
I use Lua mainly from inside Emacs, and I do most of my coding using REPLs, using eepitch and test blocks... and my favorite way of doing OO in Lua is with eoo.lua, that (ta-da!) is very REPL-friendly.
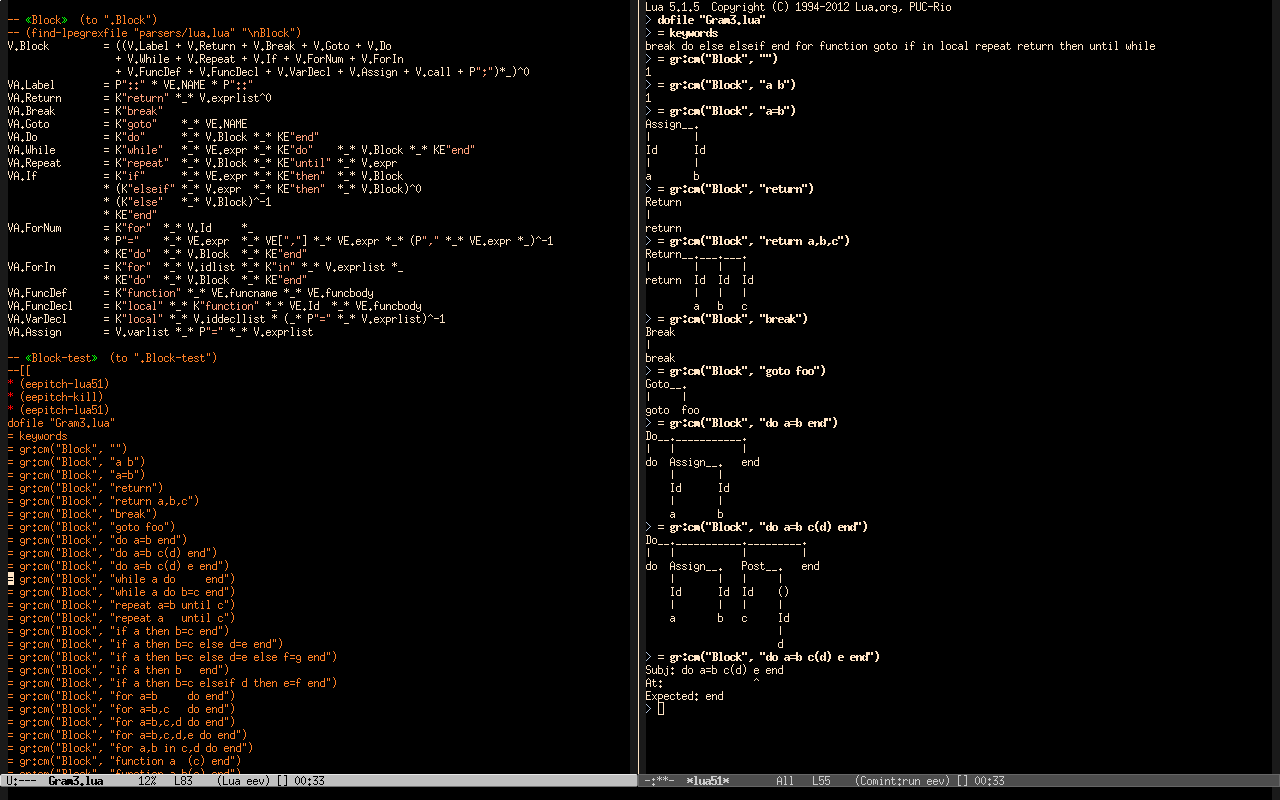
So: I decided to learn lpegrex, because it looked like a great tool for writing complex grammars - for example, its grammar for Lua is just this... but I quickly found that 1) it has too many concepts to me, 2) I would like to make lots of small changes and extensions to it, 3) its code is not REPL-friendly at all, 4) the best way to do all that would be to rewrite lpegrex in my style, factoring it in another way, as a lower-level half that is a series of extensions to Lpeg, and on top of that an upper-level half that is an (extensible) re-like language.
1. A prototype: Gram1.lua
This file - Gram1.lua - implements the core ideas and nothing else. It starts with a test block - here - that shows how we can build grammars step by step in a REPL using just plain Lua and Lpeg, and then it defines a class - Gram - that lets us do that, i.e., to build grammars step by step in a REPL, in a more convenient way. Here is a screenshot of its test block:
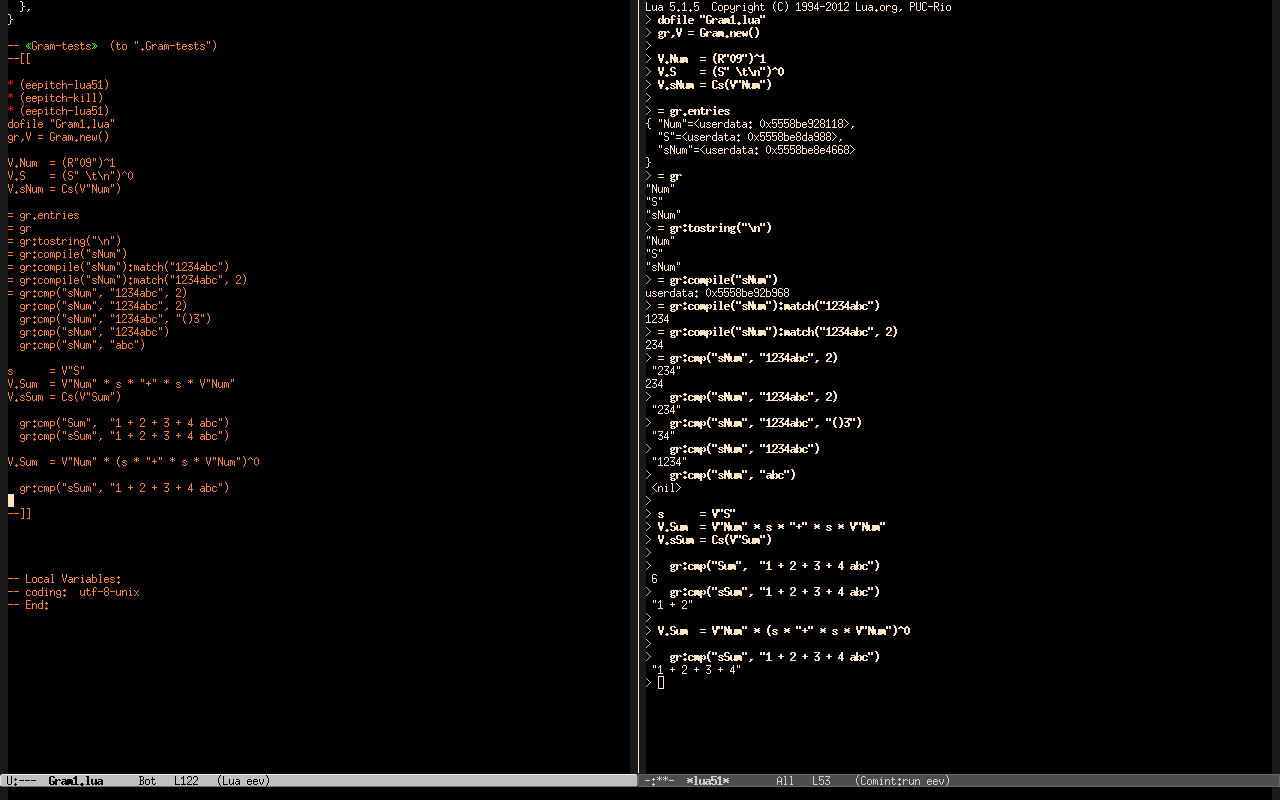
An object of the class Gram holds an "uncompiled grammar". The class Gram defines methods for compiling that grammar (:compile), for compiling and matching (:cm), and for compiling, matching and (pretty-)printing the result (:cmp).
2. Everything: ELpeg1.lua
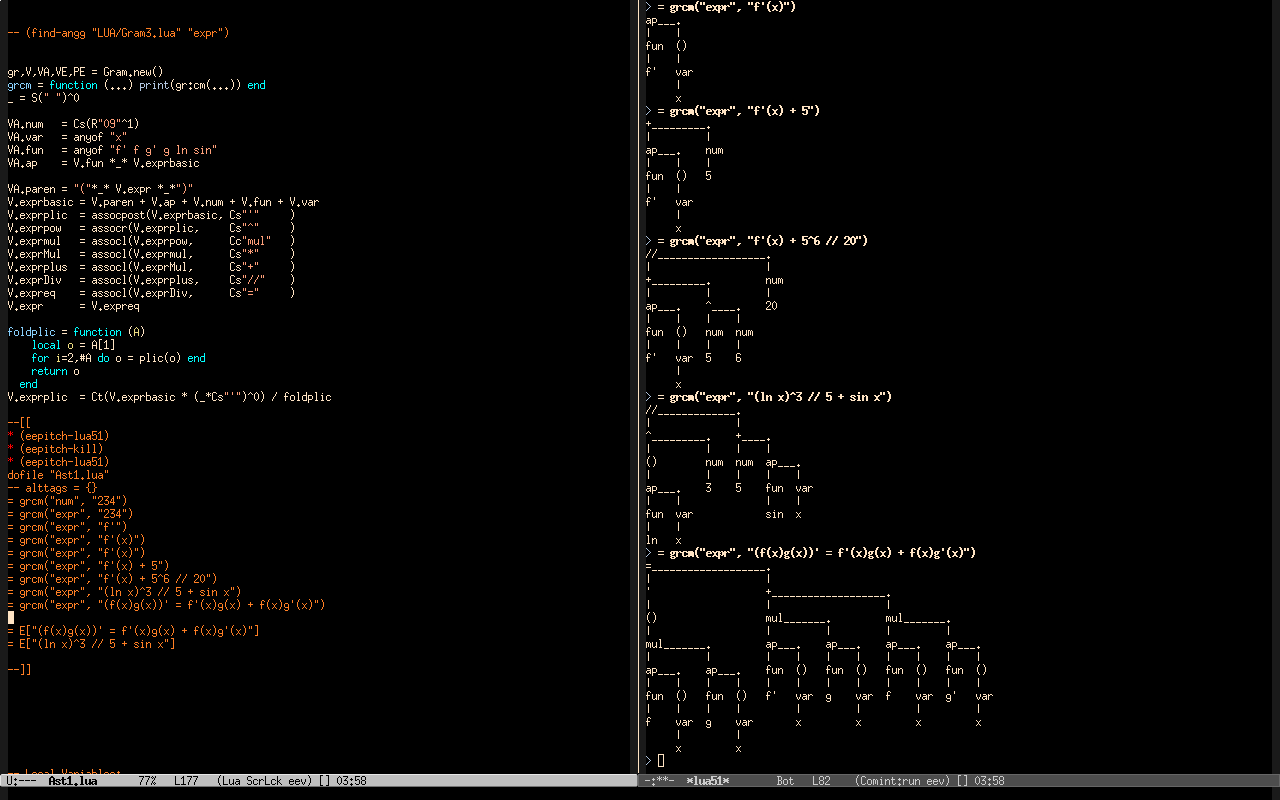
The name LPegRex means "LPeg Regular Expression eXtended". My hacked version of it is called ELpeg, where the "E" means lots of things at the same time: extended, Emacs, eev, and eepitch... and we can also think that it is "REPL lpeg" with several letters dropped.
The file ELpeg1.lua is quite big, but it is composed of several parts - most of them classes - than can be tested separately:
- AST implements support for ASTs that are printed as trees.
- E lets me draft how some ascii strings are to be parsed. (Screenshot?)
- Cast: Cast("tag", lpegpattern) is similar to lpeg.Ct(lpegpattern), but Cast returns an AST with the tag "tag". Cast be changed to include fields "pos" and "endpos" in the AST, like lpegrex does here; these fields would not be shown when the ASTs are drawn as trees.
- Expected implements a simplified version of lpegrex's "expected matches".
- Gram is like Gram1.lua, but on steroids - it contains code for interacting with many other classes.
- Keywords implements a simplified version of lpegrex's support for keywords and tokens.
- LpegDebug and GramDebug implement a simplified version of Paul Kulchenko's PegDebug and of lpegrex.debug - but my version lets us select which entries of an uncompiled grammar will receive debugging code.
- The sections called folds, anyof, assocs, and endingwith define several functions that receive lpeg patterns and build more complex patterns from them; some of them suppose that the global variable _ holds a pattern for whitespace; compare with lpegrex's SKIP. Note that it is trivial to define these "parser combinators" in lpeg but it is hard to modify re to define new parser combinators in it... and lpegrex is a kind of re.
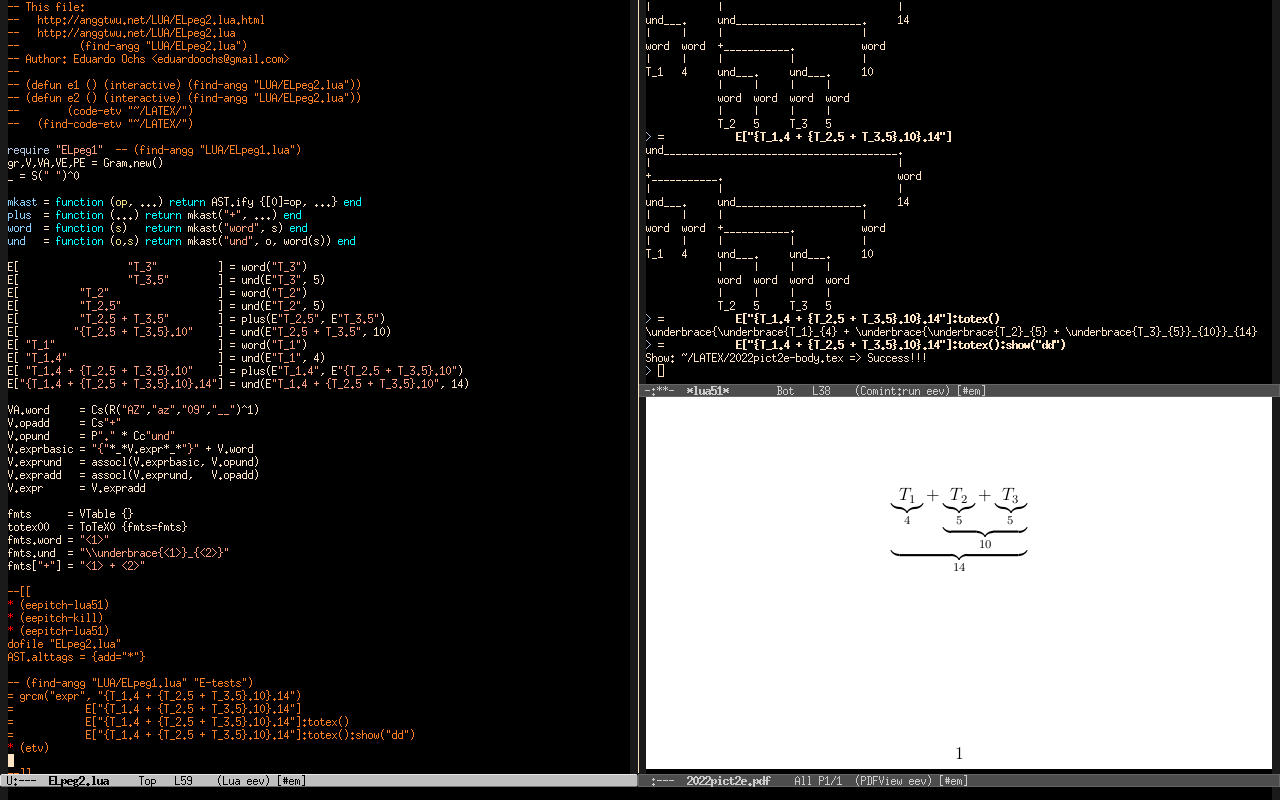
- The classes ToTeX0 and ToTeX let us define ways to convert ASTs to LaTeX code.
- (TODO Explain totex and show)
TODO: rewrite all the rest!
(find-angg "LUA/ELpeg1.lua") (find-angg "LUA/Gram1.lua") (find-angg "LUA/Gram2.lua") (find-angg "LUA/Gram3.lua") |